Rigas Kouskouridas |
Home - Research - Publications - Projects |
Object recognition, detection and 6D pose estimation | ||
 |
6D Object Detection and Next-Best-View Prediction in the Crowd - CVPR 2016 6D object detection and pose estimation in the crowd (scenes with multiple object instances, severe foreground occlusions and background distractors), has become an important problem in many rapidly evolving technological areas. Rather than using manually designed features we a) propose an unsupervised feature learnt from depth-invariant patches using a Sparse Autoencoder and b) offer an extensive evaluation of various state of the art features. To further improve 6D object pose estimation, we propose an improved joint registration and hypotheses verification module as a final refinement step to reject false detections. | |
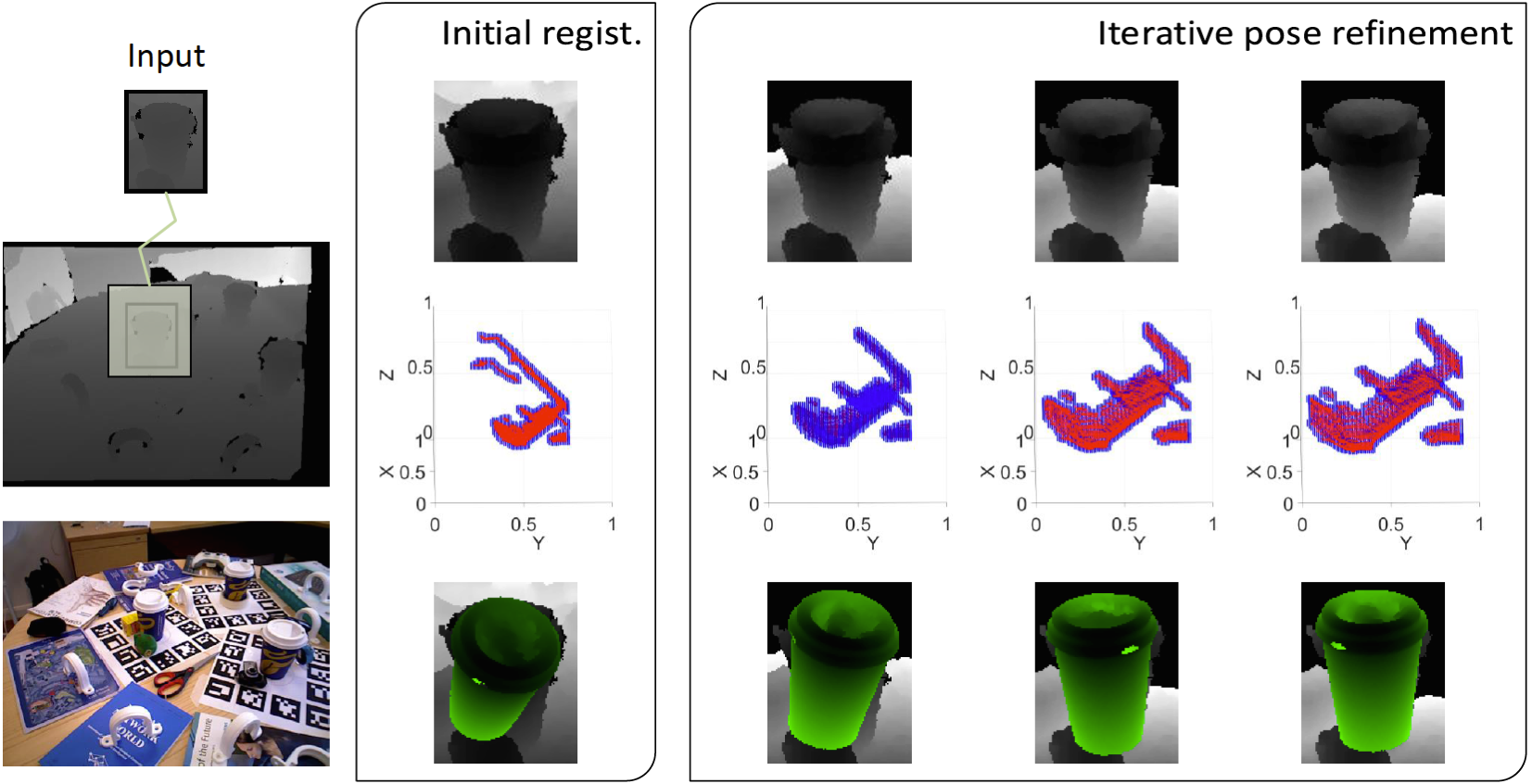 |
State-of-the-art techniques for 6D object pose recovery depend on occlusion-free point clouds to accurately register objects in the 3D space. To reduce this dependency, we introduce a novel architecture called Iterative Hough forest with Histogram of Control Points that is capable of estimating occluded and cluttered objects' 6D pose given a candidate 2D bounding box. Our iterative Hough forest is learnt using patches extracted only from the positive samples. These patches are represented with Histogram of Control Points (HoCP), a scale-variant implicit volumetric description, which we derive from recently introduced Implicit B-Splines (IBS). The rich discriminative information provided by this scale-variance is leveraged during inference, where the initial pose estimation of the object is iteratively refined based on more discriminative control points by using our iterative Hough forest. We conduct experiments on several test objects of a publicly available dataset to test our architecture and to compare with the state-of-the-art. | |
 |
Latent-Class Hough Forests for Object Detection and Pose Estimation - ECCV 2014 In this paper we propose a novel framework, Latent-Class Hough Forests, for 3D object detection and pose estimation in heavily cluttered and occluded scenes. We adapt the state-of-the-art template matching feature, LINEMOD, into a scale-invariant patch descriptor and integrate it into a regression forest using a novel template-based split function. A a by-product, the latent class distributions can provide accurate occlusion aware segmentation masks, even in the multi-instance scenario. In addition to an existing public dataset, which contains only single-instance sequences with large amounts of clutter, we have collected a new, more challenging, dataset for multiple-instance detection containing heavy 2D and 3D clutter as well as foreground occlusions. We evaluate the Latent-Class Hough Forest on both of these datasets where we outperform state of the art methods. | |
 |
Efficient Feature Representation for 3D Object Pose Estimation - Neurocomputing 2013 Following the intuition that different objects observed from similar viewpoints share identical poses, we designed and implemented a novel approach that incorporates a robust constellation structure and sparse manifold modeling for 3D object pose recovering. Our work is highly motivated by the remarkable skills exhibited by humans in the particular task of finding the relative pose of objects given an initial hypothesis. We treat the constellation structure problem from an unsupervised learning perspective and address the manifold modeling issue as conforming an ellipse over the extracted constellation points. We then formulate it as a combinatorial optimization problem using the Particle Swarm Optimization (PSO) tool and graph analysis techniques. In learning a representative description of a 3D object pose model, our algorithm requires limited supervision during the learning process whilst resulting in a problem of reduced dimensionality. | |
Robot vision - object manipulation, grasping | ||
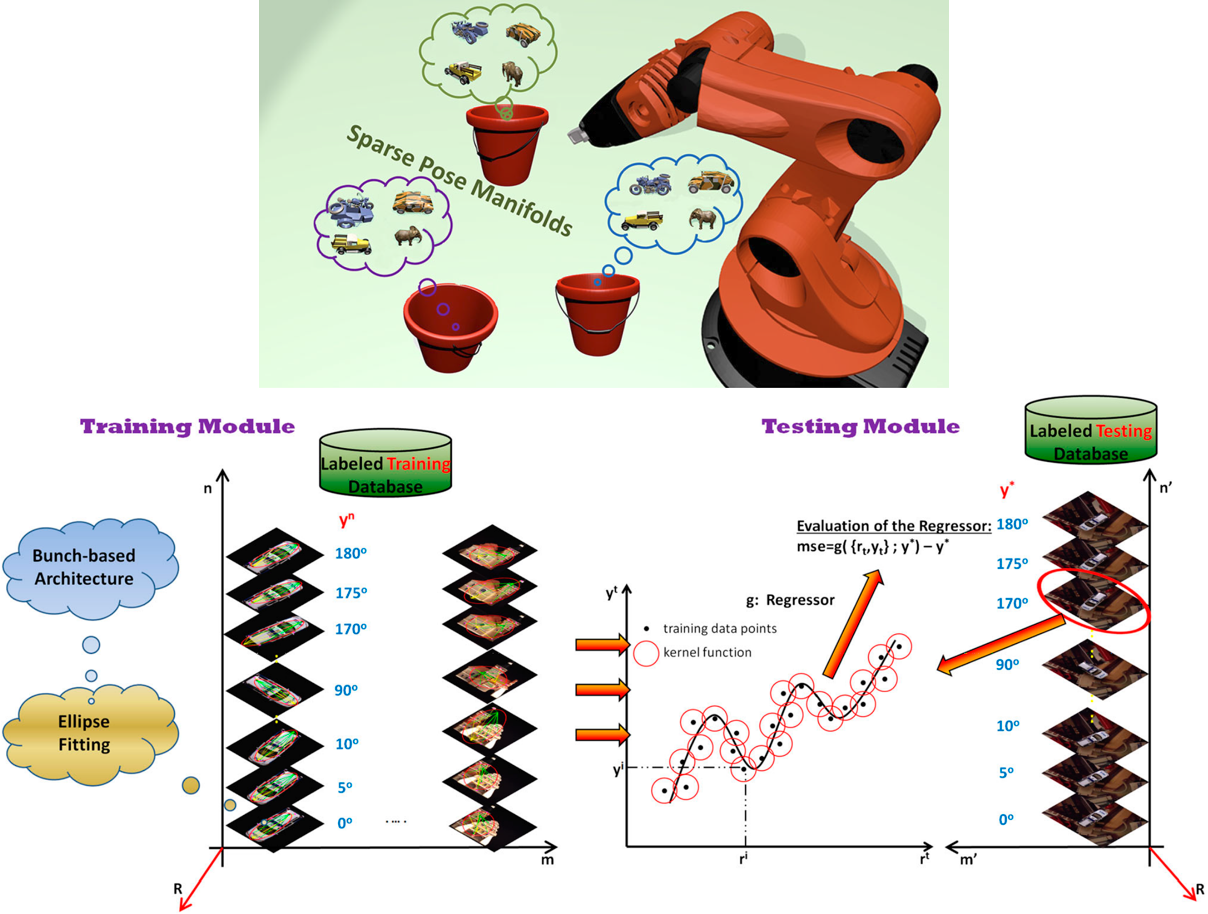 |
Sparse Pose Manifolds - Autonomous Robots 2014 We introduce for the first time the term of grasping manifolds that are formulated on a bunch-based structure incorporating unsupervised clustering of the abstracted visual cues and encapsulating appearance and geometrical properties of the objects. The resulting grasping manifolds represent the displacements among any of the extracted bunch points and the two foci of an ellipse fitted over the members of the bunch-based structure. We post-process the established grasping manifolds via L1 norm minimization so as to build sparse and highly representative input vectors that are characterized by large discrimination capabilities. While other approaches for robot grasping build high dimensional input vectors, thus increasing the complexity of the system, our method establishes highly distinguishable manifolds of low dimensionality. This paper represents the first integrated research endeavor in formulating sparse grasping manifolds, while experimental results provide evidence of low generalization error justifying thus our theoretical claims. | |
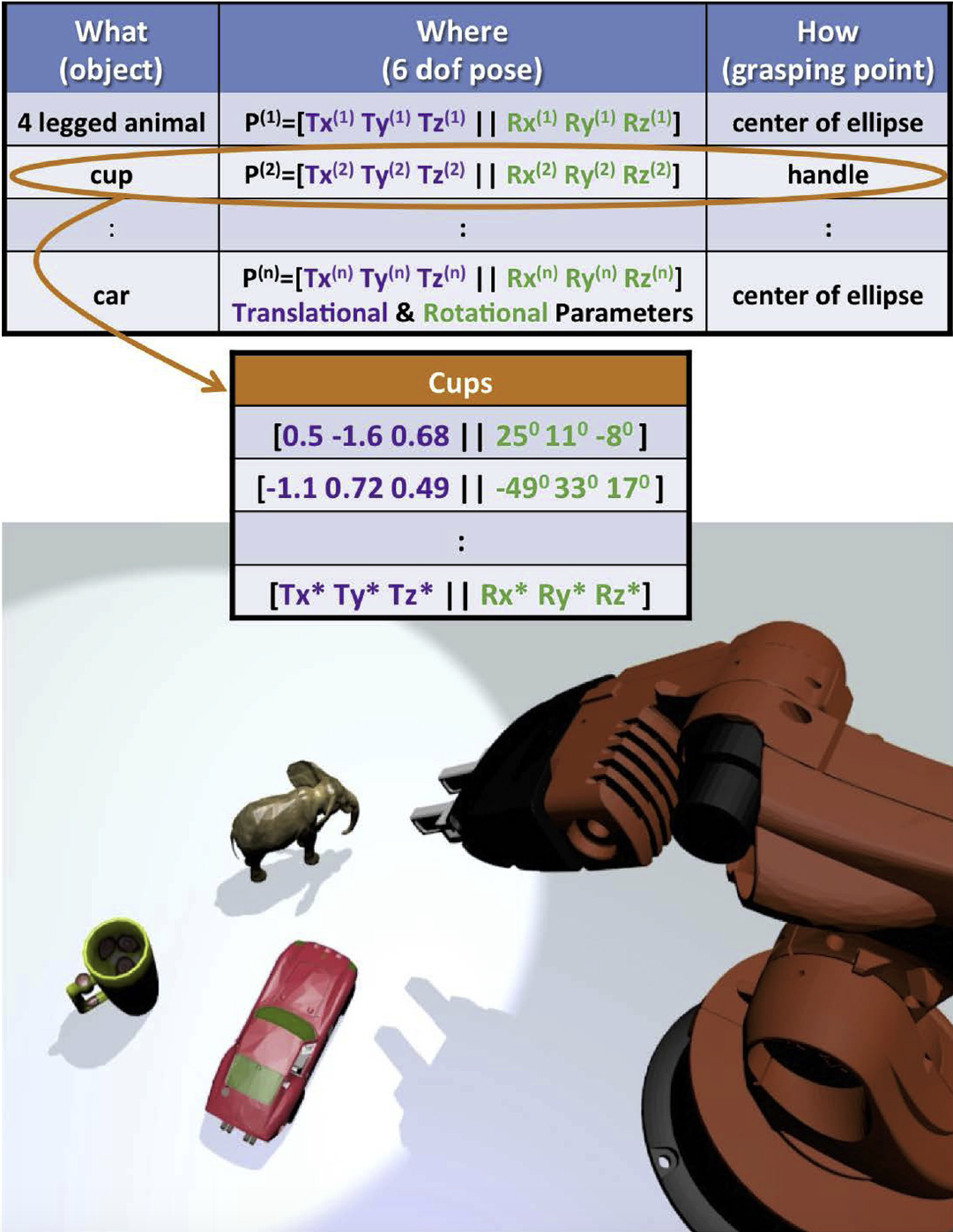 |
In this paper, we aim at designing a unified architecture for autonomous manipulation of unknown objects, which is capable of answering and addressing the constraints of all the following questions: “What is the object?”, “Where is it?" and “How to grasp it?". Towards this end, we address the recognition problem from a shape-based perspective, whilst obtaining accurate detection decisions via a Bag-of-Visual Words classification scheme. Moreover, the 6 DoF pose estimation module is based on the intuitive idea that even different objects when observed under the same viewpoints should share identical poses that can be projected onto highly discriminative subspaces. Grasping points are found through an ontology-based knowledge acquisition where recognized objects inherit the grasping points assigned to the respective class. Our ontologies include: a) object-class related data, b) pose-manifolds assigned to each instance of the object-class conceptual model and c) information about the grasping points of every trained instance. | |
Illumination invariant feature detection - description | ||
 |
This paper presents a new illumination invariant operator, combining the nonlinear characteristics of biological center-surround cells with the classic difference of Gaussians operator. It specifically targets the underexposed image regions, exhibiting increased sensitivity to low contrast, while not affecting performance in the correctly exposed ones. The proposed operator can be used to create a scale-space, which in turn can be a part of a SIFT-based detector module. The main advantage of this illumination invariant scale-space is that, using just one global threshold, keypoints can be detected in both dark and bright image regions. In order to evaluate the degree of illumination invariance that the proposed, as well as other, existing, operators exhibit, a new benchmark dataset is introduced. It features a greater variety of imaging conditions, compared to existing databases, containing real scenes under various degrees and combinations of uniform and non-uniform illumination. Experimental results show that the proposed detector extracts a greater number of features, with a high level of repeatability, compared to other approaches, for both uniform and non-uniform illumination. This, along with its simple implementation, renders the proposed feature detector particularly appropriate for outdoor vision systems, working in environments under uncontrolled illumination conditions. | |