Sparse Pose Manifolds
Autonomous Robots 2014
 |
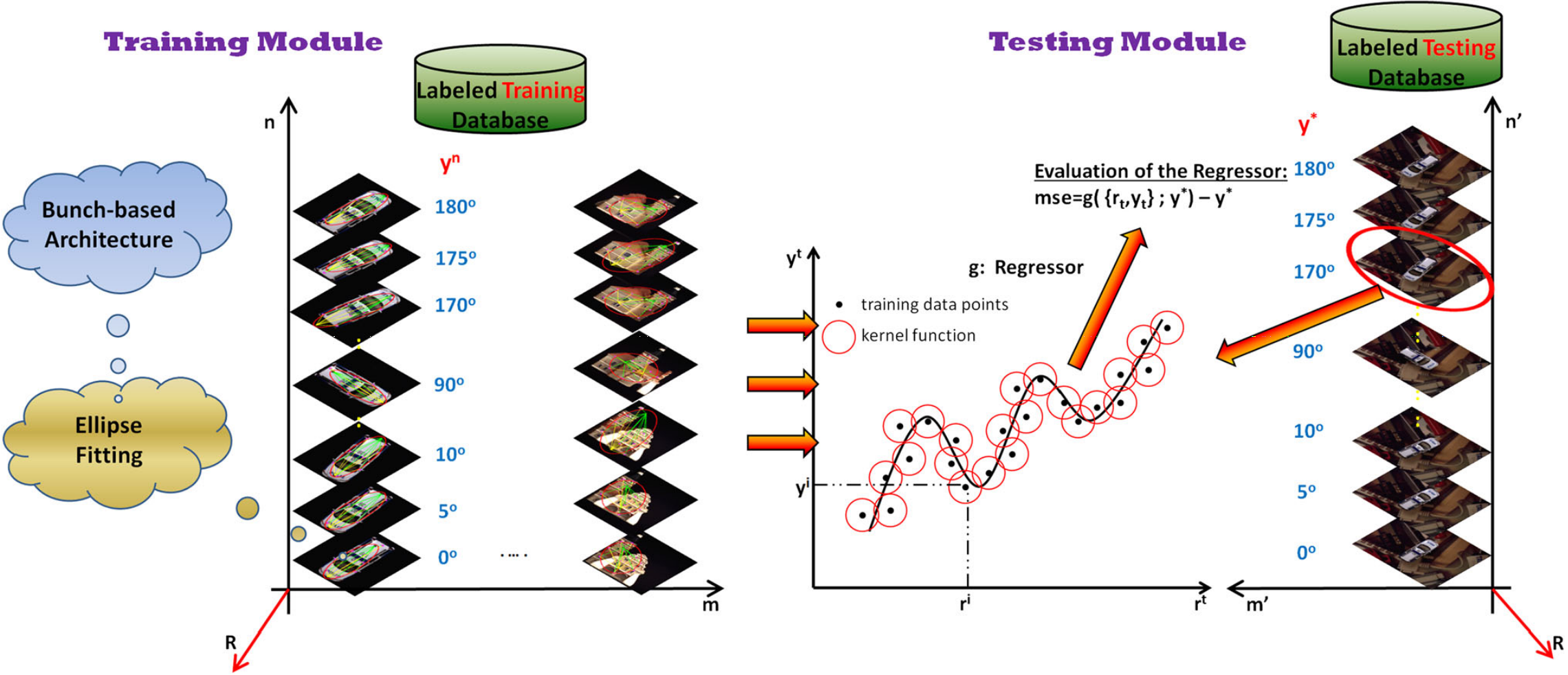 |
The efficient manipulation of arbitrarily placed objects depends on the estimation of their 6 DoF geometrical configuration. In this paper we tackle this issue by following the intuitive idea that different objects, viewed under the same perspective, should share identical poses and, moreover, these should be efficiently projected onto a well-defined and highly distinguishable subspace. This hypothesis is formulated here by the introduction of grasping manifolds relying on a bunch-based structure that incorporates unsupervised clustering of the abstracted visual cues and encapsulates appearance and geometrical properties of the objects. The resulting grasping manifolds represent the displacements among any of the extracted bunch points and the two foci of an ellipse fitted over the members of the bunch-based structure. We post-process the established grasping manifolds via L1 norm minimization so as to build sparse and highly representative input vectors that are characterized by large discrimination capabilities. While other approaches for robot grasping build high dimensional input vectors, thus increasing the complexity of the system, our method establishes highly distinguishable manifolds of low dimensionality. This paper represents the first integrated research endeavor in formulating sparse grasping manifolds, while experimental results provide evidence of low generalization error justifying thus our theoretical claims. The following videos demonstrate the efficiency of our method for eye-in -hand (box car) and eye-to-hand (box tool) camera configurations.
Contributions
- The proposed Sparse Pose Manifolds method lays its foundations on a novel module for pose manifold modeling that establishes compact and highly representative subspaces,whilst experimental verification provide evidence for the existence of such manifolds, sufficient to facilitateunknown object grasping.
- Pose manifolds depend on a novel bunch-based architecture (here introduced for the first time) which, unlike previous works is able to bypass the part selection process using unsupervised clustering, whereas by extracting local patches, encapsulates both appearance and geometrical attributes of the objects.
- Extending earlier work reported in Mei et al. (2009, 2011) where 3D pose estimations are limited to cars, we utilize numerous databases of real objects available that are further expanded by new artificially generated ones. In addition, compared to previous work our method offers higher generalization capacities mainly due to the efficient learning based on a large a priori training set containing numerous examples of real and artificial data.
- The established manifolds exhibit low dimensionality, thus avoiding the usage of conventional dimensionality reduction schemes widely employed in several computer vision applications. Besides, through the minimization of the l1 norm we build sparse and compact manifolds that are highly representative, tolerant to common imaging disturbances (e.g. noise) and superior in terms of discrimination capabilities.
- Comparative evaluation of our work against other related works demonstrates its superiority in 3D pose estimation and object manipulation tasks. Quantitative and qualitative experimental results provide evidence of high 3D pose recovery rates with low generalization error, whist real time execution boost the potential of our work.
Results
Eye-in-hand camera configuration videos
Eye-to-hand camera configuration videos